7x24 Automatically Submit Thousands of Jobs to CSE GPGPU Cluster
July 11, 2020
Edit (Nov 7 2024): This post was written back in 2020 at CUHK. Things might have changed a lot and the article might be very obsolete now.
Background
Recently I’ve been working on a machine learning project, so it comes inevitable to do some time-eating finetuning tasks. Obviously, it would be infeasible to tune thousands of combinations of hyperparameters all on my laptop. As a result, I turn to CSE’s GPGPU computing cluster, hoping their TITANs can help. The computational power is great, but meanwhile, it’s also quite underwhelming as they put a very annoying limit for the users —
At most 4 running/pending tasks at the same time.
Well, this is fine as long as you don’t have lots of parameters to tune (which should be the normal case). However, as the number goes up, it soon becomes tedious to submit all your jobs by hand. Some may alleviate the problem by merging small jobs into a larger one, but doing so is also demanding in the sense that you still need to worry about the maximum running time of each job, and the scripts are pretty much not reusable.
After wasting a non-trivial fraction of my life playing with the CSE server, I’ve finally decided to come up with something that could solve this problem (hopefully), that is slurmmy.
slurmmy comes with a command line interface. It reads the shell commands for the jobs, then keeps on watching the slurm queue continuously. Once a running job terminated, a new one will be submitted automatically via sbatch. So ideally, as long as slurmmy is running, it can assure you there are always 4 jobs running.
To further squeeze every second for computing, it’s also possible for slurmmy to gather jobs into a larger one to reduce slurm’s scheduling overhead, or, additionally let slurmmy leverage process-based parallelism to further speed up the computation if your jobs are cpu-bottlenecked.
You can check out the GitHub repo for more details and please give it a ⭐ if you find it helpful, 🙏。
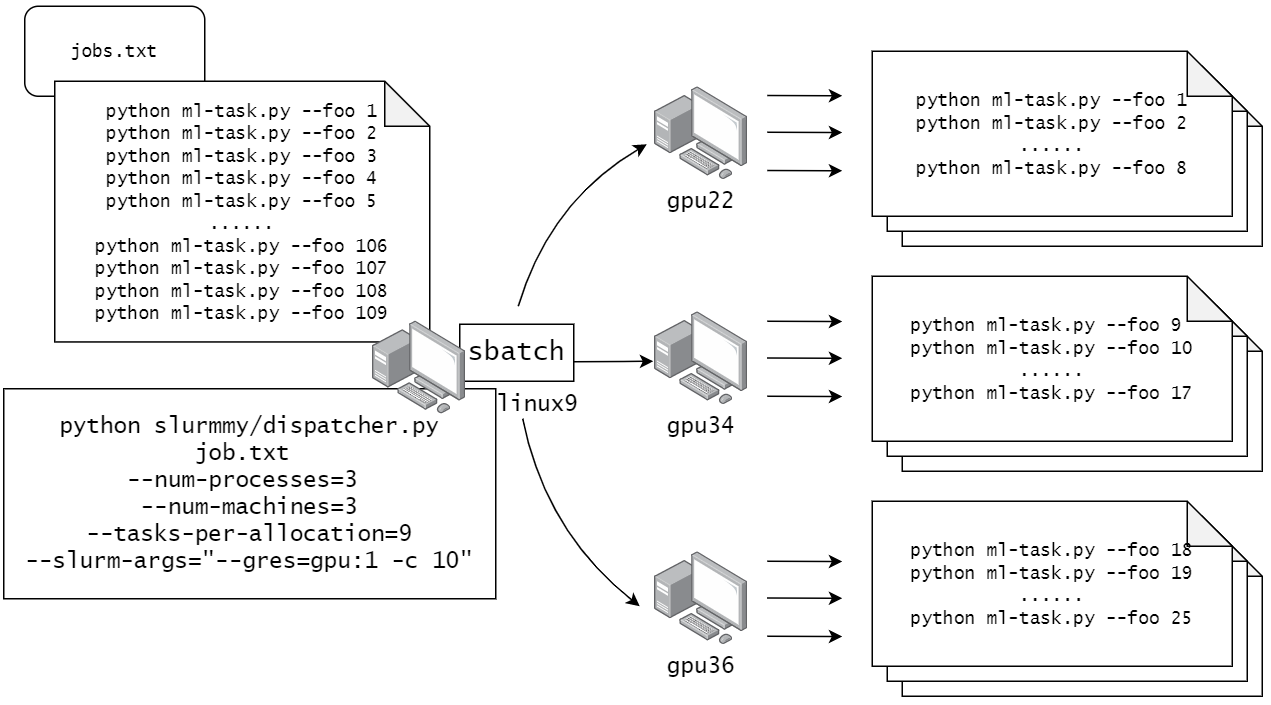
An example for CSE cluster
sshto linux6-19- Get ready the jobs you want to run. Write (Generate) the shell commands for them into a text file, say
my-tasks.txt. Each command takes a single line - Clone
slurmmyif you haven’t done so. Then invokeslurmmy/dispatcher.pywith the arguments as per your need. Usenohupwhen appropriate.
Ah, time for 😪
Tips
- Use
nohup+&ortmuxto keep it running even after your current session ends. - Change
--tasks-per-allocationand--num-processesto get parallel execution of multiple tasks on computing nodes. Note that--num-processesshouldn’t exceed the number of cores, i.e.-cfor slurm. - Use templates to get more flexibility like email notification.
- Keep an eye on the rebooting schedule of the Linux servers. Odd/Even numbered linux servers reboot on the first Monday of odd/even numbered months.